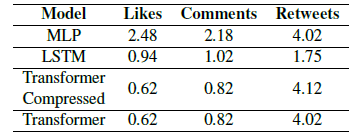
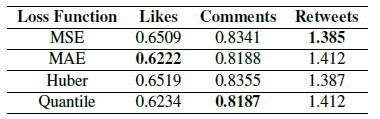
About Me
Hello! I am a Computer Science graduate from the University of Southern California.
I am passionate about leveraging data-driven solutions to solve complex problems and drive innovation. With a solid foundation in statistical models, deep learning, and hands-on projects experience, I excel at transforming raw data into actionable insights. Let's connect and explore how we can harness the power of data to create impactful change!
What I'm Doing
Data Science
2-4 years of experience in Data Science, focusing on predictive modeling, statistical analysis, and machine learning
Machine Learning Engineering
2-4 years of experience in MLE, working on deploying and optimizing machine learning models
Data Engineering
0-2 years of experience in Data Engineering, building and maintaining data pipelines and ETL processes
Data Analysis
0-2 years of experience in Data Analysis, providing actionable insights through data visualization and reporting
Domain Experience
Healthcare
Experience in leveraging data for healthcare analytics and predictive modeling to improve patient outcomes.
Automobile
Worked on projects involving vehicle data analysis, predictive maintenance, and automation techniques.
Education
Developed educational tools and analytics platforms to enhance learning experiences and outcomes.
Agriculture
Implemented data-driven solutions for crop prediction, soil health analysis, and precision farming.